


About the Project
In 2023 I started studying AI, machine learning and related areas. I started with tutorials and courses but soon realized I wanted to apply this knowledge to gaming. This led me to create the Pong AI Challenge, my first project built from the ground up, in which I aimed at training an AI agent to play Pong using Reinforcement Learning.
This project was developed in Python. I used Pygame for rendering and event handling, Open AI's Gym and Stable Baselines 3 for training a DQN model in a custom environment, and Optuna for hyperparameter optimization.
The project features three different Game Modes:
-
AI vs. Human: Where a human player can compete against the AI agent.
-
AI vs Dummy: Watch the AI agent play against a basic deterministic "dummy" AI that only tracks the ball's vertical position (Y position) without any strategic play.
-
AI vs AI: Watch two AI agents, trained identically, compete.
I developed this project over the course of 5 weeks, working an average of 2 hours per day on it.
In the following section, I'll discuss the project's progress over time.
It's important to note that I'm a game designer with an interest in coding, rather than a professional programmer. Therefore, my code might not meet professional standards, and some tasks took longer than they might for an experienced programmer. However, embracing these challenges is also part of my learning journey!
Week 1 - Setup and basic game logic
The first week was all about creating the foundation for the project. I set up the development environment and learned Pygame basics. Following this, I developed the core game loop, allowing me to play as Player 1 against a deterministic "hard coded" AI. This AI's strategy was simple: if its paddle's vertical position (Y) didn't align with the ball's, it would move to match it, capped at a maximum speed per frame.
I quickly noticed that even this simple "AI" proved to be a challenging opponent due to its almost instant paddle adjustments, making it difficult for me to score unless the ball's movement unexpectedly exceeded the AI's speed limit. This led me to modify the game's logic for a more balanced and interesting gameplay.
Here's an overview of my custom Pong mechanics:
-
The game begins with the ball at the center of the playfield. Its initial direction (left or right) and speed (X and Y velocities) are randomly determined within predefined limits to ensure each game starts slightly differently.
-
Players can move their paddles up and down within a fixed speed limit. Paddles do not accelerate.
-
Each time the ball collides with a paddle, its speed increases.
-
This increase in speed is randomized within certain limits for both X and Y velocities.
-
Hits near the paddle's extremities result in a bigger speed boost than hits near the center.
-
The goal is for this randomness to make the game more dynamic and in the future to encourage the AI to learn, adapt and eventually exploit these mechanics.
-
-
If the ball hits the screen's top or bottom, its Y velocity reverses, but there's no increase in speed.
-
A goal is scored when the ball touches the field's left or right edge.
-
The first player to reach 10 points wins the game.
These mechanics were designed to introduce unpredictability and challenge, as the ball's speed will eventually exceed the paddle's, requiring strategies beyond merely mirroring the ball's vertical position. To create a more forgiving deterministic AI, I could have added a reaction delay, but my goal was to test whether my AI Agent could overcome this challenge.
After tweaking the game variables, this was the outcome at the end of the first week:

Week 2 - Adding the AI Agent
During the project's second week, my focus shifted to the AI agent. In the context of machine learning, an AI agent is an autonomous entity capable of making decisions and taking actions to achieve specific goals. After some research about the best approach for an AI agent that needs to learn how to play Pong, I decided to use a Deep Q Learning (DQN) agent as it seemed fit for the type of problem I was trying to solve.
With OpenAI's Gym and Stable Baselines 3, I created a custom environment where the AI agent's observation space (training inputs) included:
-
Paddle's Y position
-
Ball's X and Y position
-
Ball's X and Y speed
Next, I designed the reward system, which is how the agent measures success. In Reinforcement Learning, the agent pursues actions leading to rewards and avoids those resulting in penalties. In this first iteration, I defined the rewards as follows:
-
Agent scores: Reward
-
Opponent scores: Penalty (negative reward)
Last but not least, the agent could perform the following actions:
-
Move paddle up
-
Move paddle down
-
Don't move the paddle
After some troubleshooting, I managed to train the agent for approximately 1 hour and... apparently it didn't learn anything. Actually, that's not true, the agent learned to position itself in the screen's corner, periodically shifting from one corner to another.
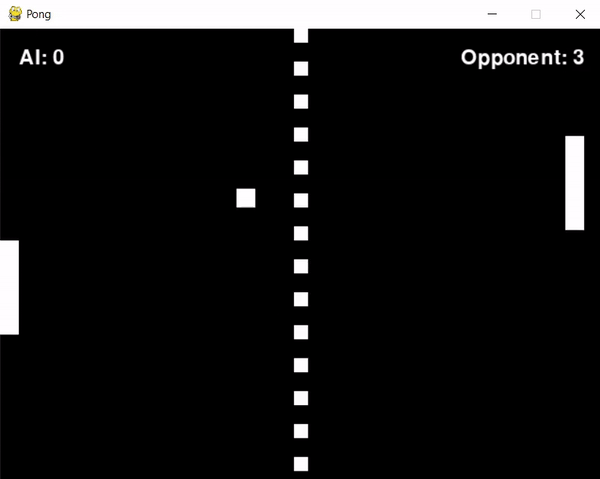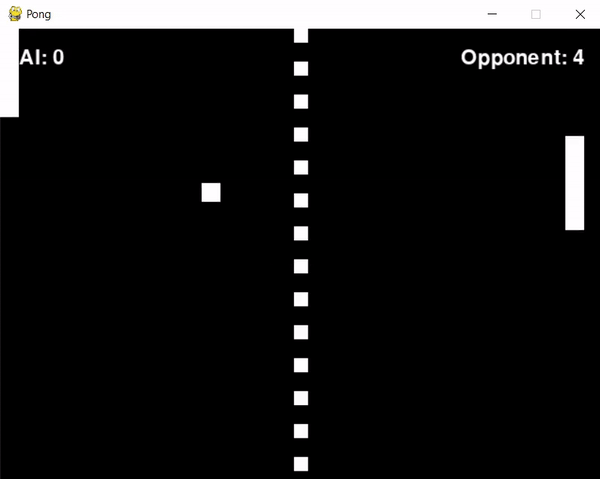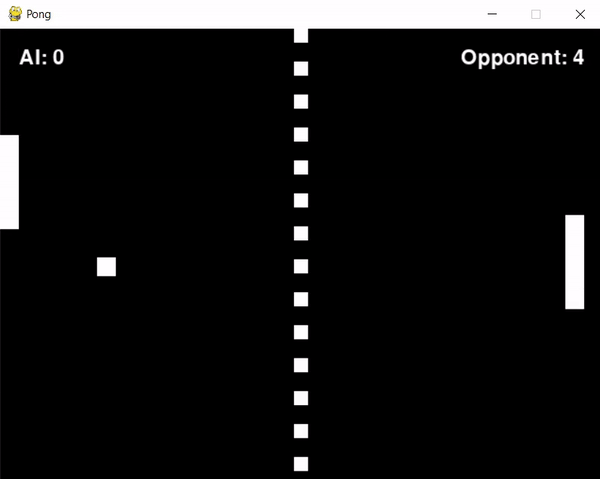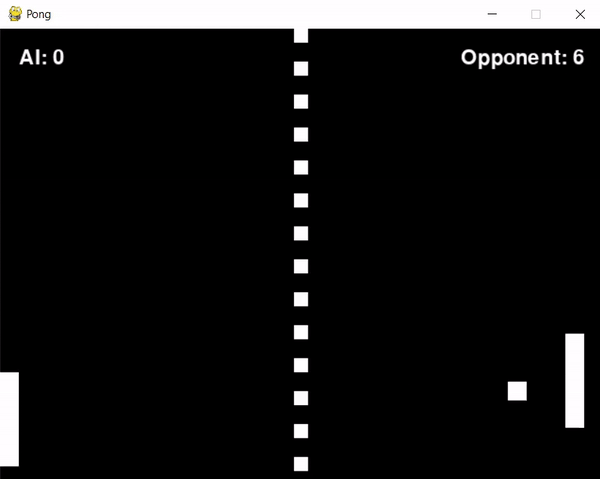
Reflecting on this behaviour and examining the reward system led me to some insights:
-
The opponent's aggressive play style resulted in it scoring frequently.
-
This led to the agent receiving penalties (negative rewards) more often than not.
-
At the same time, the agent struggled to score, which meant it rarely received positive rewards.
-
Consequently, the agent didn't learn effective strategies for earning rewards but instead learned to minimize penalties.
-
It probably figured out that cornering itself would slightly reduce the frequency of penalties, due to a slightly higher chance of hitting the ball.
With that in mind, I made the following adjustments:
-
Decreasing the paddle speed for the opponent.
-
Decreasing the paddle's sizes so it became easier to score.
-
I included a small reward for hitting the ball.
-
I included a very small reward if the ball's Y position was within the agent's paddle vertical height.
-
Changed the discount factor (gamma) value to 0.9. This value is used to balance immediate and future rewards; a value of 0.9 means future rewards are valued at 90% of their immediate value, prioritizing long-term gains over short-term rewards.
After training the agent for 8 hours (20M timesteps), the results were already much better, it was even able to engage in rallies against the opponent!
Week 3 - Optimization
Following the progress made in week 2, I shifted my focus towards refining the model through hyperparameter optimization. Initially, I cleaned up my code and made some game adjustments such as narrowing the paddles, tweaking their placement, and correcting collision inconsistencies.
To tackle the optimization, I used Optuna, a tool designed for automating the tuning of model hyperparameters. This open-source framework aids in maximizing a model's performance by experimenting with multiple configurations of hyperparameters—like learning rate, gamma, and exploration rates—over a series of trials.
In my case, Optuna assessed the model's performance across 50 trials, each consisting of 1000 episodes (matches), where it adjusted the hyperparameters within predefined limits. The goal was to pinpoint the set of hyperparameters that led to the highest average reward.
After running Optuna for approximately 1 day, the set of hyperparameters that achieved the highest mean reward was:
-
Learning rate: 0.0001 - Determines how much the model updates its knowledge in each training step, with a smaller value leading to slower but more stable learning.
-
Batch size: 256 - The number of training examples used to update the model's weights.
-
Gamma: 0.88 - The discount factor used to balance immediate and future rewards.
-
Buffer size: 10000 - The size of the memory buffer that stores past experiences for replay and learning.
-
Exploration Initial: 0.928 - The initial probability of choosing a random action over the best action, encouraging initial exploration of the state space.
-
Exploration Final: 0.025 - The final minimum probability of taking a random action, ensuring some level of exploration even after extensive learning.
-
Exploration Fraction: 0.257 - The fraction of the entire training period over which the exploration rate is reduced from its initial to its final value, controlling the pace of reducing exploration.
To effectively monitor the agent's learning, I integrated Tensorboard. This tool provides a visual representation of the agent's training progress, allowing for detailed comparison and analysis of its performance over time. With it, I can analyze various metrics like average rewards, episode durations, exploration rates, and train/loss. The train/loss metric is particularly useful as it measures the variance between the agent's predicted action values and the actual rewards obtained from the environment. The main goal of the agent is to reduce this loss incrementally, thereby refining its policy for better decision-making.

After training an agent for 1 hour with the hyperparameters obtained through Optuna, these were the results:
This was incredibly promising! The agent's performance had noticeably improved compared to its predecessor, and it accomplished this in a significantly shorter training duration. Motivated by these results, I extended the agent's training to a full day.
Weeks 4 & 5 - Final touches
After these partial successes, I made several adjustments and tests over the next 2 weeks. To list a few:
-
Implementation of the main menu
-
UI improvements
-
Implementation of multiple game modes
-
Extra parameters to monitor on Tensorboard
-
Increased the opponent's speed to match the agent's speed, etc.
During this phase, not every experiment turned out as planned. A persistent problem was the agent's tendency to "give up" on pursuing the ball during crucial moments. In instances like the one illustrated below, it seemed possible for the agent to intercept the ball in the final frame had it continued its movement. Instead, it stopped short, abandoning the effort at the last second.
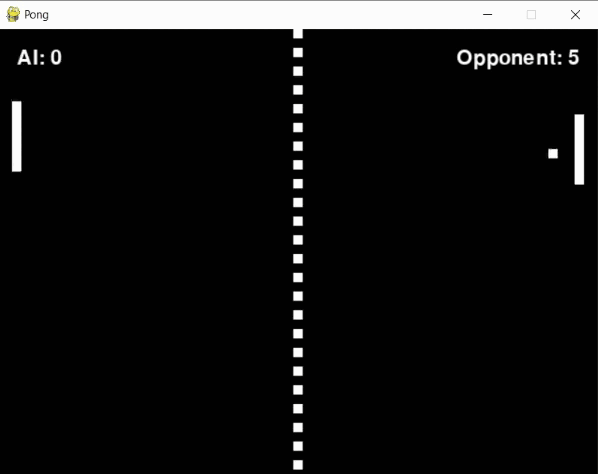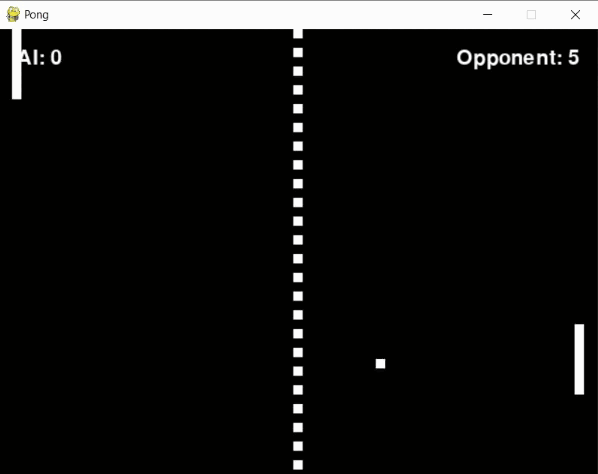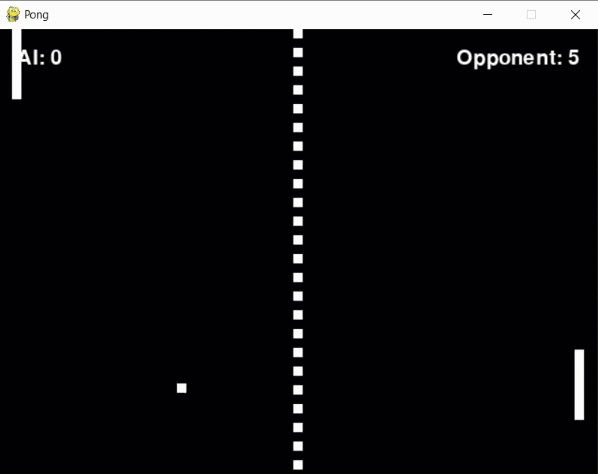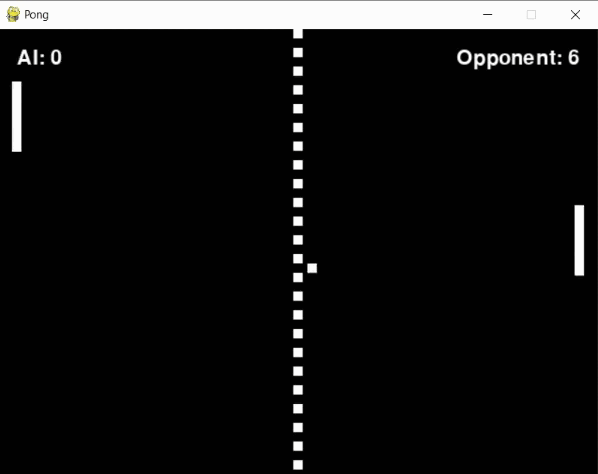
To address this, I introduced a "blunder" penalty. This penalty was applied when the ball was within a reasonable range of the paddle (+-30 pixels) but the agent failed to hit it, adding to the penalty received when the opponent scored. However, this approach didn't work as expected. Instead of improving, the agent's performance dropped, likely because the additional penalty introduced too much noise into its learning process.
After several attempts to make this work, I decided to scrap the extra penalty. In its place, I added two new variables to the observation space: flags indicating when the ball hits each paddle. My hope was that this would help the agent understand the direct consequence of missing the ball.
With these changes, I initiated an extensive training session for what I hoped would be the final agent version, setting it to train for an entire week. The graphs below track both the score and the number of matches won by each side, with "player" representing the AI agent and "opponent" being the deterministic AI. The initial day brought encouraging outcomes, with the agent winning about 40% of the matches at its best. However, something unexpected happened next. The agent's performance began to decline sharply:

I encountered what I believe to be my first instance of "Catastrophic Forgetting," a phenomenon where the AI struggles with game states that are similar yet lead to vastly different outcomes, causing confusion in the learning process. There are a few things we can do to avoid catastrophic forgetting, such as reward normalization and using a replay buffer (specifically in DQN models).
Given I was aiming to complete this project within a month and my limited familiarity with the concept of replay buffers, I've decided to focus on implementing reward normalization for now. Tweaking the replay buffers would require significant changes to my code and as I was already deep in week 4 of this project, I aimed to maintain the scope manageable.
After implementing reward normalization and restarting the training, the results initially seemed very promising. However, after another day and a half, the agent experienced another episode of catastrophic forgetting, though it managed to recover after an additional day. Unfortunately, it fell into yet another episode from which it couldn't recover, marking a significant setback in the training progress.

Following those setbacks, I opted for a new strategy. Rather than doing long training sessions, I limited it to roughly 2 days—coinciding with when catastrophic forgetting typically occurred. This change led to much more stable training (prior to the collapse) and yielded improved outcomes, as evident in the graph below (green line). At its peak, the agent was winning over 60% of the matches!

And here's a glimpse of the final result:
Learnings and next steps
To say I learned a lot with this project is an understatement. Concepts I previously understood only in theory turned into tangible results in front of me.
Despite the agent’s imperfections, I’m quite satisfied with the outcome. Sure, it makes some odd mistakes, but watching it engage in a rally against the opponent is incredibly rewarding. Building a reinforcement learning agent from the ground up in a custom setting, especially as someone who isn't a professional programmer, was a big challenge. I see this as a major accomplishment and deem the project a success despite the flaws.
Here are my key learnings from this project and adjustments for future endeavours:
-
Using Replay Buffers: I came across the concept of Replay Buffers relatively late into the project. Understanding now how crucial they are in DQN models, I'd definitely prioritize incorporating them correctly from the beginning in any future projects.
-
Catastrophic Forgetting: This was a new challenge for me and a common issue in reinforcement learning scenarios. I feel I am now better prepared to address this in future projects.
-
Training Duration vs. Performance: While familiar with this idea from smaller-scale projects, this was my first time witnessing that extended training periods don't necessarily lead to improved outcomes on larger scales.
-
The value of Hyperparameter Optimization: Although I was aware of its importance, this project showed me the dramatic improvements that can be achieved through hyperparameter tuning.
-
Designing an effective reward function: Designing a reward function was a first for me and involved much trial and error. Going forward, I aim to simplify and normalize reward functions early on to mitigate catastrophic forgetting.
While I don't know what my next AI project will be, my passion for this field only grows stronger.
Thank you for reading my development diary!